
Multi-Agent Reinforcement Learning for Flappy Bird
Some experiments with Deep Q-learning for a Pygame implementation of Flappy Bird. We specfically wanted to see whether Deep-Q learning could be extended to multi-agent settings while still retaining the benefits of learning from raw sensory input. Each agent has its own action-value approximation function with no shared parameters; the code scales nicely to allow for arbitrary agents.

Deep Recurrent Neural Networks for Question Answering
A summary of deep learning algorithms for question answering for this year's thesis project, mostly focusing on Weston et al's Memory Neural Networks and their variants, such as the Neural Reasoner, that are applied to Facebook's BabI dataset. The QA task here is not factoid question answering, which is traditionally an information extraction task, but answering questions that require inference over facts that are local to a given scenario (i.e. there is no knowledge base on the internet containing the relevant data, you only have the facts that you are told). This is a challenging new frontier that requires understanding the relationships between entities that may change over time, and then doing inference over accumulated knowledge. These tasks bring the NLP community one step closer to interactive and predictive dialogue systems.

Multi-armed Bandits and Regret
I was curious about how the CS Theory community approached the kind of problems the ML community faces in the reinforcement learning setting. It turns out that if you ignore the notion of a state space and only consider an action space, you can guarantee "good" behavior even if rewards are adversarially assigned. Adversaries and theoretic guarantees are something the reinforcement learning (and even ML) community has struggled to pin down, so it was very refreshing to compare and contrast the two fields, especially with respect to their objectives (regrets vs. discounted rewards) and techniques for tracking the best actions (similar to boosting).

Multiview Linear Chain Conditional Random Fields
CRFs are graphical models that encode a conditional probaibility distribution, which holds several advantages over joint distributions (HMMs), namely, the ability to more quickly compute the normalizing constant. Many common time series tasks such as phone recognition use the viterbi algorithm to find the best sequence of labels. Here we modify the famous conditional random field algorithm to incorporate multiple views of the data, which has been shown to dramatically constrain the complexity of learning. This is a presentation, along with soon-to-be published code, describing the algorithm and comparing it to HMMs.

A Comparison of Deep Methods for Canonical Correlation Analysis on Phoneme Recognition
The primary advantage of multiview learning in the realm of classification is the ability to incorporate multiple modalities of the same phenomenon for learning. For example, today's social media world allows for photos, text, locations, friend tagging, and audio recordings to be part of a single "post". A classifier can be trained for each modality, and in the case of subspace learning, the correlation objective can be applied to all classifiers simultaneously to yield better performance than a classifier trained in isolation. Canonical Correlation Analysis lends itself well to situations wherein one modality of the data should be predicted or reconstructed from the other modalities. Such is the case for phoneme recognition in speech processing. This project explores a range of nonlinear classifiers for recognizing phonemes in the XRMB dataset. Since it was just released (at the time of writing), Tensorflow was used to implement the deep techniques.

Stochastic and Incremental algorithms for Linear Subspace Learning for Facial Identification
Often times data sets are too large or high dimensional to be sensible. Perhaps the data contains redundant, unnecessary, or uninformative features. For example, out of the several million pixels representing a persons face in an image, how many of those are necessary to determine the subject's identity? Subspace learning answers this question by finding a suitably small subspace of the data that retains information needed to reconstruct the original data with minimal loss. This project describes, replicates, and compares the state of the art stochastic and incremental methods to subspace learning and applies them to the well known Yale Face Dataset.

Parsing
Extracting meaning from raw text is a difficult task. There are many ambiguities in natural and formal text arising from synonymy, polysemy, syntactic, and lexical ambiguities. Consider one of my favorite examples from Dr. Eisner: "Time flies like an arrow". Is this a command to time fruit flies quickly? Or that the abstract notion of time moves quickly? Or that a certain species of insect known as the time fly happen to like a particular arrow? Fortunately, while each of these parses is possible, some are more likely than others in the context of large corpora. Earley's algorithm, implemented here with a few optimizations, is a way to construct the most likely parse tree from a grammar of smaller context-free rules composed by dynamic programming. There are several great resources to learn how this well-studied algorithm works. Photo: http://www.sanjaymeena.net/

Random Forests
Classification by Majority Vote of a Forest of Decision Trees
Random Forests are some of the most popular, thoroughly studied, and widely used classifiers. A major contribution came from Leo Breiman's paper discussing variance reduction for classical information-theoretic decision trees by randomized training of a community of classifiers. The solution is basically to take the majority vote from the many trees each trained on a subsample of the data with randomized selection of test attributes. On a related note, I also implemented boosted decision trees for comparison
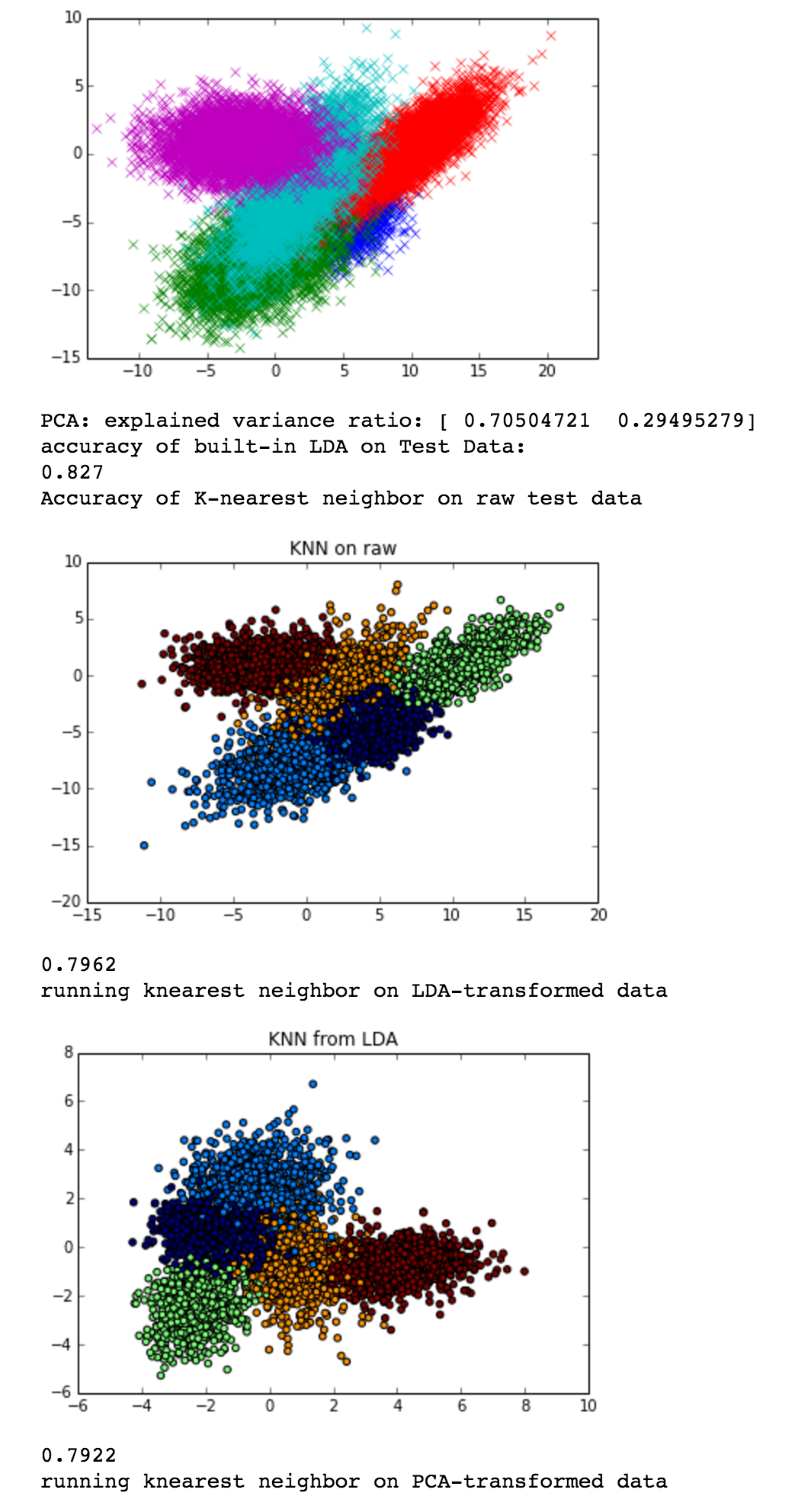
Linear Discriminant Analysis
Comparison of LDA and PCA for Subspace Learning in Classification Settings
PCA and LDA learn linear subspaces but with different objectives; my goal here was to develop an intuition about when it was suitable to use these algorithms for dimensinality reduction, if at all. PCA attempts to find a subspace that captures maximal variance and reconstructive ability. LDA takes into account class labels and seeks a maximally discriminative subspace of the data. However, both have their weaknesses. PCA is unable to discern between two classes if they both lie along approximately parallel principle components. LDA, on the other hand, is only able to discern between classes that exhibit large mean separation and captures none of the variance within the classes.
I also wanted to check out ipython notebooks, and they're really fun!

Literature Review of Online Decision Tree Classification Algorithms
Independent Research
This paper summarizes the most impactful literature of online decision tree (ODT) algorithms. These classification algorithms are designed to handle extremely large datasets or data streams with high frequency. Learning decision trees in an online setting is a natural topic for investigation if one is already familiar with the basic batch algorithms. They are also more practical from a business and engineering standpoint, as they are proven to perform asymptotically as well as a batch learner.

Reinforcement Learning: A Comparison of Value Iteration and Q-learning Algorithms in a Markov Decision Process
Abstract: In this paper we apply two different reinforcement learning algorithms to a Markov Decision Process (MDP). The first is value iteration (VI) with full knowledge of the environment’s stochastic state transition model, the second is Q-learning (Q), which does not require the model. We found that VI converges to a near-optimal solution more quickly, but given the right input functions and parameters, Q yields slightly better performance, especially when the reward function is particularly harsh. Both agents exploited interesting “loopholes” in the environment to achieve better scores. We recommend using VI to solve an MDP whenever enough information exists...

Decision Trees: A Comparison of Genetic and Information-Theoretic Classification Trees
A paper describing my first interaction with, and comparison of, some of the canonical decision tree learning algorithms on UCI data sets.
In this paper I compare the performance of decision trees constructed by two different machine learning algorithms on binary classification problems. The first is an information-theoretic algorithm that selects for attributes which most aggressively reduce entropy in the training set. The second is a genetic algorithm that borrows the concept of natural selection to build populations of decision trees probabilistically. I show that while the performance of the algorithms is similar, the underlying flexibility of the genetic algorithm allows for broader coverage of the solution space in hope of finding a good local maximum, but at the cost of tuning its numerous parameters to that solution space.

Respirage: A Respiratory Rate Measurement Device for Emergency Department Triage
My biomedical engineering design team's final report summarizing the design and testing results of our medical device's prototype.
We designed a portable, non-invasive vital sign measurement device for the fast-paced environment of emergency department triage.
Read the Paper View Presentation Emsol Health View Disclosure

MoleSniffer
Cancer Diagnostics Mobile App
At the 2014 HopHacks (JHU hackathon) competition, we developed an Android app to detect early stages of melanoma via computer vision algorithms. We placed 3rd overall, and were winners of the JHU Social Innovation Lab’s Award for the greatest impact on society, for which we were offered a spot in their startup incubator and seed funding.

MATLAB Simulation of SIR Model for Infectious Disease
Final project for a Biomedical Modeling and Design class at JHU comprising. I implemented a MATLAB simulation of the spread of contagious diseases based on commonly used models in epidemiology. We won "highest honors" for the project out of our class.

Microstereo Lithography for 3D printing CAD objects
A year-long project in high school with the Mechanical Engineering dept. at the UIUC to design a cheaper alternative to high-precision 3D printing. We designed a novel method to print large flat objects by polymerizing a liquid with UV radiation so that they do not bend/buckle. On my own time, I printed a working combination lock entirely out of our polymerized liquid. We presented our results at the world-famous UIUC Engineering Open House.

Effects of Abrasion on Chlorophyll Fluorescence
Year long high school research project with the late Dr. Robert Clegg, former chair of the Biophysics Department at the University of Illinois Urbana-Champaign

Special Relativity Presentation
Based on Stanford EPGY's Special Relativity Course I attended over the summer of 2012
A semester capstone project for senior year independent study

Stabilization of Inverted, Vibrating Pendulums
Physics C Final Project
A neat experiment about the stability of dynamical systems.